


Презентация демоверсии разработки
Голосовые помощники, вопросно-ответные системы на основе искусственного интеллекта и чат-боты становятся все популярнее. В будущем они могут стать одним из стандартных пользовательских интерфейсов. Но ответы, которые выдают диалоговые системы, все еще недостаточно точны. Ученые Пермского Политеха с коллегами из Германии предложили новый подход, с помощью которого можно повысить качество их ответов более чем на 19%. Это позволит сделать «общение» человека с компьютером более естественным. У разработки пока нет аналогов в мире.
Исследование было представлено в 2022 году на международной конференции European Semantic Web Conference в Греции и вызвало высокий интерес у представителей научного и профессионального сообществ, а прототип разработки вошел в тройку лучших демоверсий, по мнению жюри. Метод рекомендовали внедрить в существующие вопросно-ответные системы. Результаты работы ученые опубликовали в журнале The Semantic Web. ESWC 2022. Lecture Notes in Computer Science.
– Голосовые помощники, чат-боты, устройства на основе искусственного интеллекта и интернета вещей становятся неотъемлемой частью повседневной жизни. Но до сих пор существуют проблемы, связанные с качеством и точностью результатов, которые выдают вопросно-ответные системы. Низкий уровень достоверности информации вызывает негативное отношение к таким сервисам у общества, особенно у людей старшего поколения. Давать компактные и правильные ответы на вопросы пользователей – сложная задача, поэтому мы повысили именно эти показатели с помощью нашей разработки, – рассказывает одна из разработчиков, доцент кафедры иностранных языков и связей с общественностью Пермского Политеха, кандидат филологических наук, доцент Мария Ельцова.
В отличие от поисковых систем, которые предоставляют пользователю множество ответов, диалоговые интерфейсы должны выдавать только один ответ. Поэтому качество информации имеет решающее значение для широкого распространения таких устройств.
Почти все вопросно-ответные системы на основе баз или графов знаний работают по одинаковому принципу. Сначала в них поступает вопрос от пользователя. Затем формируются запросы на специальном языке, например SPARQL, к базе данных, хранящей информацию в виде графа знаний (Knowledge Graph). После этого система выдает возможные варианты ответов, среди которых происходит выбор одного, как правило, случайным образом. При таком подходе точность результатов достаточно низка. Поэтому исследователи предложили еще на этапе генерации запросов исключать все неверные варианты с помощью их вербализации и валидации.
– Новый подход сокращает время на обработку запросов и показывает значительное улучшение качества ответов на вопросы. Для оценки нашего подхода мы использовали известную и признанную эталонной в научном сообществе вопросно-ответную систему «QAnswer». Нам удалось повысить точность ответов на 19,5%, а показатель F1 – на 19,2%, что является очень весомым результатом, – отмечает исследовательница.
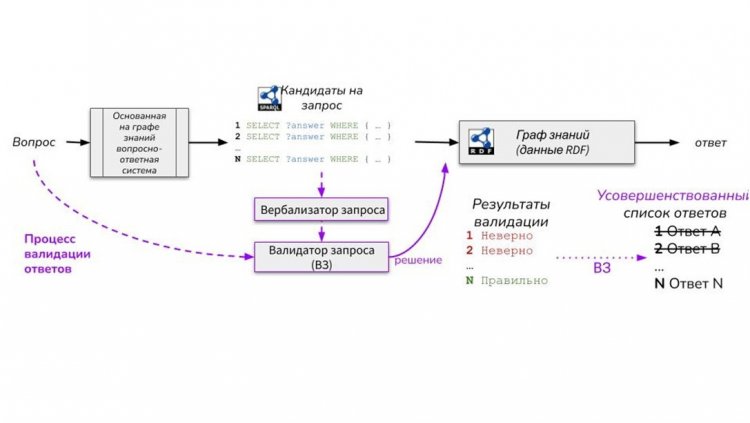
Процесс и метод, который был изобретен учеными
Использовать разработку можно будет в сфере искусственного интеллекта, интернета вещей и других областях, где применяют пользовательские интерфейсы на основе «общения» человека с компьютером. Новый метод также сможет улучшить качество работы поисковых систем, так как они будут выдавать больше релевантных запросов в начале.
Уникальность метода состоит в том, что его можно применять к любой основанной на графе знаний системе. Результаты достигнуты на базе английского языка, в дальнейшем ученые планируют адаптировать разработку и для других языков.
Источник информации и фото: пресс-служба Пермского Политеха
























{kind=link}