

Научная группа iMolecule из Сколтеха разработала решение, которое на основании данных о структуре РНК и ДНК предсказывает участки этих молекул, пригодные для взаимодействия с предполагаемыми лекарственными веществами. Зная эти так называемые сайты связывания, можно более эффективно и целенаправленно находить формулы новых препаратов, в том числе противовирусных. Представленное в журнале Nucleic Acid Research: Genomics and Bioinformatics решение использует искусственный интеллект и определяет сайты связывания точнее, чем аналоги, поскольку учитывает влияние пространственной конфигурации молекулы на доступность сайтов.
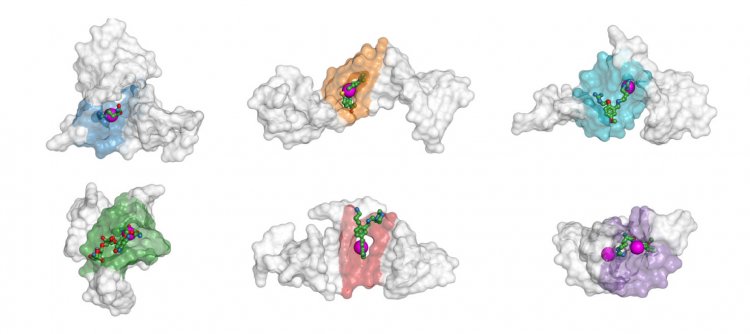
Серые фигуры соответствуют шести пространственным конфигурациям одной и той же РНК-последовательности ВИЧ. Она является мишенью многих противовирусных средств, таких как показанные здесь цветными шариками соединения. Представленная учёными из Сколтеха нейросеть предсказывает наличие сайтов связывания там, где изображены крупные розовые сферы. Видно, что они соответствуют расположению достоверно известных сайтов, которые затенены синим, оранжевым и т.д. Источник: Игорь Козловский, Пётр Попов/NAR Genomics and Bioinformatics
Долгое время фармакологи видели в РНК лишь посредника между инструкциями в нашем геноме (ДНК) и закодированными в них функциональными белками — мишенью большинства лекарств оставались сами белки. При этом известно, что белки закодированы лишь в ничтожной части тех 85% генома, с которых транскрибируется РНК. Оставшаяся, некодирующая РНК участвует в регуляции генов или выполняет иные функции, зачастую принимая определённую конформацию, то есть пространственную конфигурацию. Поскольку процессы с участием некодирующей РНК тоже могут вносить вклад в развитие заболеваний, последовательности РНК — и ДНК тоже — всё чаще рассматриваются как потенциальные мишени для лекарств.
«Нуклеиновые кислоты, ДНК и РНК, участвуют, например, в передаче сигналов и других процессах, на которые можно медикаментозно воздействовать. Такой подход, в частности, может подойти для заболеваний, в которые вовлечены неупорядоченные белки или белки без доступных сайтов связывания, — объяснил руководитель исследования, старший преподаватель Сколтеха Пётр Попов. — Вдобавок к тому бывают чужеродные РНК и ДНК, например вирусные, — коронавирус, ВИЧ и т. д., которые являются одними из основных мишеней при борьбе с патогенами».
Чтобы раскрыть потенциал всех этих предполагаемых мишеней лекарств, фармакологам нужны инструменты для перебора огромных баз химических соединений — таким образом устанавливают, какие из них взаимодействуют с той или иной нуклеиновой кислотой и посредством каких сайтов.
«В основе нашего решения лежит аналогичная работа с белками, — пояснил Попов. — Трёхмерные структуры нуклеиновых кислот кодируются в виде высокоразмерных тензоров. Затем алгоритм компьютерного зрения „смотрит“ на тензоры и ищет области, похожие на сайты связывания. После детектирования конформации и сайта связывания можно начинать целенаправленную работу по поиску лекарств. Таким образом, наша работа — это часть перехода от слепого перебора к рациональному дизайну лекарств. Превосходство последнего с ростом библиотек соединений становится всё заметнее».
Одно важное преимущество нового решения связано с тем, что молекулы ДНК и РНК из-за своей формы склонны сворачиваться и принимать разные конформации — при этом меняются их свойства, в том числе доступные сайты связывания. Традиционные подходы отталкиваются от последовательности нуклеиновых кислот, то есть «буквенного кода», но игнорируют конформацию, что является большим недостатком.
«К тому же большинство прежних методов были применимы только к РНК, причём именно к одиночной цепи. А наш работает с ДНК и двумя или более цепями, и мы даже можем детектировать сайты, возникающие „на стыке“, при взаимодействии нескольких макромолекул», — добавил аспирант Сколтеха Игорь Козловский, первый автор работы.
«Хороший пример того, почему не стоит игнорировать конформацию, связан с самым распространённым типом ВИЧ, — продолжил учёный. — У него есть участок РНК, на который нацелены многие лекарства. Но хотя последовательность нуклеиновых кислот одна и та же, при изменении конформации молекулы меняется набор препаратов, которые могут на неё воздействовать. Предсказания нашей нейросети воспроизводят этот эффект».
У нового решения есть одно неожиданное применение «задом наперёд»: можно вместо распознавания сайтов связывания на потенциальной мишени рассмотреть проблемное действующее вещество. Это может быть малая молекула вроде гормона, действие которой вызывает болезнь.
«Можно эти малые молекулы „отвлечь“. Для этого надо соорудить короткую последовательность нуклеиновых кислот, называемую аптамером, которая будет служить мишенью для проблемного гормона или другого вещества. На аптамере, очевидно, должен быть сайт связывания, и наше решение можно использовать для дизайна аптамеров с более сильным взаимодействием», — заключил Попов.
Источник информации и изображения: Сколтех
























{kind=link}