


Методы искусственного интеллекта постепенно проникают во все сферы деятельности современного человека. И все чаще мы слышим о приложениях в медицине. Аспирант факультета ВМК МГУ им. М.В. Ломоносова Валерий Евгеньевич Карнаухов вместе с его научным руководителем Андреем Серджевичем Крыловым работают над улучшением методов классификации гистологических изображений и учат нейросети генерировать новые.
Валерий Евгеньевич Карнаухов — аспирант факультета вычислительной математики и кибернетики МГУ.
— Как появилась идея проекта применения нейронных сетей для анализа биомедицинских технологий?
— Во время моего обучения на втором курсе аспирантуры научный руководитель предложил участвовать в конкурсе для фонда «Интеллект». Одна из тематик была связана с генеративной аугментацией изображений для применения нейронных сетей в анализе биомедицинских изображений. Мне эта тема понравилась, и мы подали заявку в фонд «Интеллект». Вскоре я узнал, что стал победителем конкурса, а коллеги из фонда предложили дальнейшее сотрудничество. С этого момента я стал заниматься генеративной аугментацией.
— Ранее у вас уже был опыт работы с биомедицинскими изображениями?
— Да, мне всегда нравились задачи, связанные с обработкой изображений методами машинного обучения. После обучения в бакалавриате СПбГУ я поступил в магистратуру на факультет ВМК МГУ и обратился к Андрею Серджевичу Крылову — одному из ведущих специалистов в области компьютерного зрения. Прошел мини-собеседование и оказался в лаборатории математических методов обработки изображений. Моя первая задача как раз и была связана с медицинскими изображениями, а именно с подавлением шума. Шум — это хаотическое появление пикселей случайного цвета на изображении.
Для обеспечения научной новизны проекта я изучил существующие подходы, определил преимущества и недостатки. Необходимо было взять за основу один из подходов и попытаться его оптимизировать.
Мне удалось найти актуальную статью, которая представляла положительный результат по шумоподавлению. Исследователи предложили эффективную связку «нейронная сеть + классический алгоритм». Именно ее мы и взяли за основу, работая над проектом.
Суть метода заключается в следующем: изображение подается на вход нейронной сети, которая его обрабатывает. Затем используется классический алгоритм, то есть простой математический метод, после чего цикл повторяется.

Валерий Евгеньевич Карнаухов — аспирант факультета вычислительной математики и кибернетики МГУ. Фото: Елена Либрик / «Научная Россия»
Необходимо было также подобрать специальные параметры как для нейронной сети, так и для классического алгоритма. Мы предложили метод, позволяющий выбирать некоторые параметры в автоматическом режиме. Так, двойной цикл обработки изображений и автоматический выбор параметров позволил повысить качество подавления шума по сравнению с результатами, которые получили ранее авторы упомянутой статьи. После этого мы с научным руководителем продолжили заниматься темой, связанной с обработкой медицинских изображений с помощью методов машинного обучения.
— Расскажите об этом подробнее.
— Сегодня методы машинного обучения показывают высокие результаты в задачах классификации медицинских изображений. Несмотря на свою высокую эффективность, методы глубокого обучения требуют большого количества размеченных изображений. Наиболее реалистичным условием для современной цифровой патологии остается наличие небольшого количества размеченных изображений. Поэтому перед специалистами стоит задача увеличить количество таких изображений, чтобы более эффективно обучать нейронные сети.
За счет чего это достигается? Например, за счет искусственной генерации на основе генеративно-состязательных сетей. Такие сети даже по небольшому набору данных способны создавать новые размеченные изображения, которые, в свою очередь, могут использоваться для обучения нейросетевых моделей классификации. Надо сказать, что задача классификации основана на предсказании классов объектов. Например, на вход подается фрагмент ткани человека. Нейросети необходимо предсказать, к какому классу он принадлежит.
Генеративно-состязательные сети остаются одним из наиболее популярных методов аугментации для генерации синтетических данных. Они состоят из двух нейронных сетей — генератора и дискриминатора. Генератор на вход принимает случайный вектор фиксированной длины и создает примеры, похожие на реалистичные, в то время как дискриминатор классифицирует входные данные как настоящие или сгенерированные. По сути, две сети обучаются одновременно и соревнуются между собой. В результате такой конкуренции дискриминатор в процессе обучения лучше различает настоящие и сгенерированные данные, а генератор создает более реалистичные примеры.
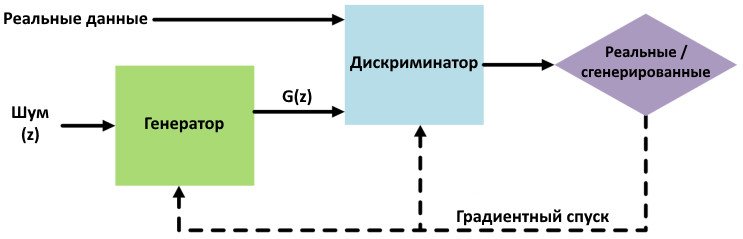
Общая схема генеративно-состязательной сети. Предоставлено В.Е. Карнауховым
— Проявляют ли интерес к вашим результатам коллеги-медики и студенты, которые учатся на медицинском факультете МГУ?
— Про студентов сказать не могу, но со стороны коллег-медиков интерес, конечно, есть.
Это задача по разработке модели, которая с высокой точностью сможет определять те или иные объекты на гистологических изображениях. При этом, если мы возьмем исходные наборы данных, то есть изображения, которые есть в открытом доступе, точность будет составлять, например, 95%. А если мы будем использовать генеративно-состязательные сети, которые обучим специальным образом, сгенерируем новые данные и уже на увеличенных наборах обучим сеть, то точность возрастает на 2–3%.
— Как вы убедились в эффективности предложенных вами методов?
— В качестве первого эксперимента для проверки гипотезы о том, что генеративная аугментация способна повысить точность моделей классификации, были выбраны случайные 500 изображений из набора данных NCT-CRC-HE-100K [1], на которых обучалась генеративно-состязательная сеть. С ее помощью были сгенерированы еще 500 новых изображений. В экспериментах было показано, что если добавить 500 новых изображений к 500 исходным и обучить модели классификации разной архитектуры на 1 тыс. изображений, то точность всех моделей повышается на несколько процентов. Те, кто занимается машинным обучением, знают, что 500 изображений — это очень мало, но даже в условиях такого ограниченного количества данных удалось показать, что генеративно-состязательные сети способны повышать точность моделей классификации.
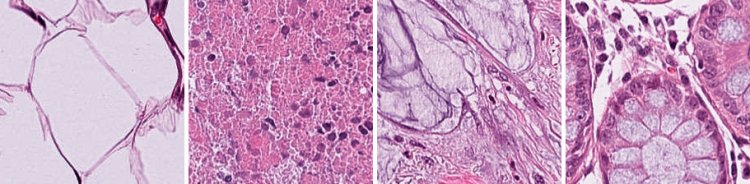
Набор NCT-CRC-HE-100K. Источник: Kather, J. N., Halama, N., and Marx, A. 100,000 histological images of human colorectal cancer and healthy tissue. 2018. Предоставлено В.Е. Карнауховым
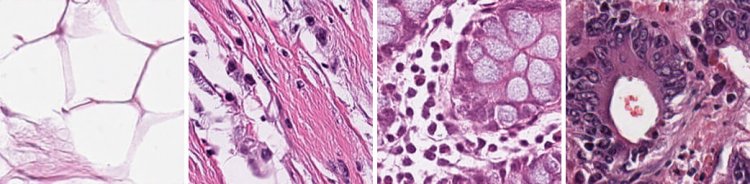
Изображения, сгенерированные для набора NCT-CRC-HE-100K. Предоставлено В.Е. Карнауховым
Для оценки эффективности применения генеративно-состязательных сетей были проведены эксперименты и на двух других наборах данных: PATH-DT-MSU [2] и BACH [3]. Здесь уже использовались все данные, а не некоторая часть, и было также показано, что генеративная аугментация повышает точность моделей классификации.





































{kind=link}