


Каждый из нас сталкивался с ситуацией, когда на экране компьютера внезапно возникает реклама того, о чем вы недавно думали. Неужели компьютеры научились проникать в наши мысли? Как современные технологии внедряются в наше сознание, распознают наш пол и выясняют наши интересы? Можно ли использовать эти технологии не только для навязчивой рекламы, но и на благо человека — например, для диагностики опасных для здоровья состояний? Обо всем этом рассказывает член-корреспондент РАН Евгений Витальевич Щепин, главный научный сотрудник отдела геометрии и топологии Математического института им. В.А. Стеклова.
— Евгений Витальевич, мы находимся в историческом месте института — библиотеке, которую собирал еще его основатель, выдающийся математик академик В.А. Стеклов. Одна из ваших научных задач — распознавание текстов. Скажите, если взять какой-то текст, например опубликованный в этой книжке, каким образом можно его математически распознать?
— Происходит это следующим образом. Сканер выдает оцифрованное изображение сканируемой страницы текста, которое представляет собой последовательность строчек: байт, которые выражают степень «серости» соответствующих точек сканируемой страницы.
Сначала оцифрованное изображение бинаризуется: если серость точки не превосходит некоторого выбранного порога, то она обнуляется, а иначе заменяется единицей. Таким образом, в компьютере изображение символа представляет собой так называемую булеву матрицу из нулей и единиц, в которой нули соответствуют фону, а единицы точкам изображения. Булева матрица символа содержит всю необходимую для распознавания информацию. Взглянув на нее, человек сразу его распознает.
— Как же его распознать компьютеру?
— Простейший матричный способ распознавания заключается в поэлементном сравнении символа с матрицами образцов, имеющихся у компьютера. Количество различающихся элементов служит мерой близости матриц. Образец, матрица которого наименее отличается от распознаваемой, и объявляется компьютером результатом распознавания, если, конечно, количество различий не слишком велико. В противном случае компьютер считает символ не распознанным.
— Таким образом можно распознать любой текст?
— Нет, к сожалению, распознавание матричным способом годится только для печатного текста и требует от пользователя долгого предварительного обучения программы. Булева матрица символа содержит всю необходимую информацию о нем, но при этом еще и слишком много избыточной. Встает вопрос: как выделить из нее существенную информацию для распознавания?
Мы придумали такой способ. Любая строка матрицы представляет собой последовательность нулей и единиц. Последовательность единиц строки, предшествуемую и завершаемую нулями, будем называть пересечением с символом, а последовательность нулей строки, предшествуемую и завершаемую единицами, — пересечением с фоном.
Если мы последовательно, двигаясь сверху вниз, заменим все строки матрицы количеством пересечений с символом, то получим последовательность пересечений, которая хотя и недостаточна для полного распознавания, но имеет долю полезной информации намного выше исходной матрицы.
Последовательность пересечений, в свою очередь, можно сократить, удалив из нее все элементы, которым предшествуют точно такие же. В результате из матрицы получится короткий код числа пересечений. Например, для буквы I в любом шрифте код пересечений состоит из единственной единицы, для V код будет 2-1, для Н код 2-1-2 и т.д.
— Вам удалось усовершенствовать код пересечений. Это так?
— Да, для этого мне пришлось проанализировать пары соседних строк матрицы. А именно, будем говорить, что пересечение символа нижней строки продолжает пересечение верхней, если один из элементов верхнего пересечения находится точно над элементом нижнего. Аналогично определяется понятие продолжения для фоновых пересечений.
Пересечения, не выступающие ничьими продолжениями из предыдущей строки, кодируются символом Р (рождение). Пересечения, не имеющие продолжения на следующей строчке, кодируются символом С (смерть). Остальные кодируются символом П (продолжение). Большинство строк матрицы символа содержат только пересечения типа П. Опустив эти строки, мы получим ПРС-код символа, который содержит существенно больше информации, чем обычный код пересечений, весьма устойчив к изменениям шрифта и даже пригоден к распознаванию рукописных символов.


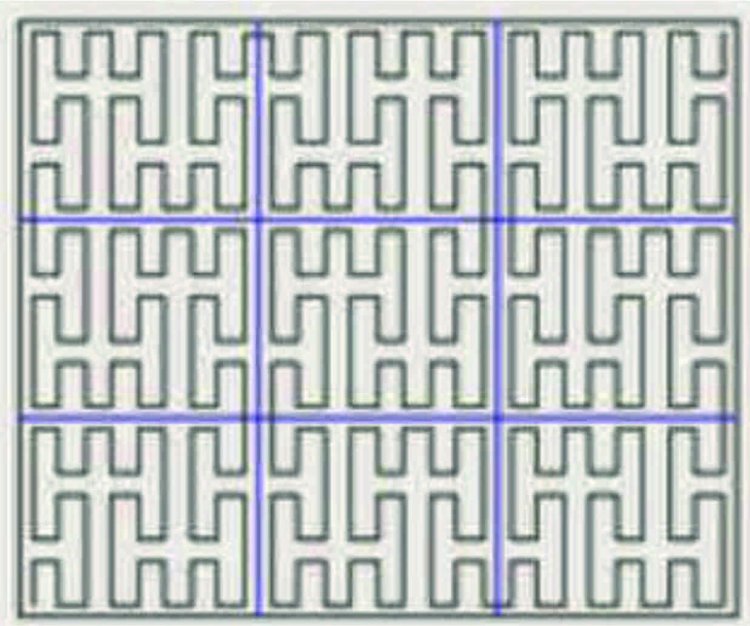

— Это почти что человеческая жизнь! А как можно записать такой код?
— ПРС-код символа можно написать по одному его виду, не зная матрицы. Например, ПРС-код буквы A будет выглядеть как Р; ПРП; ПСП; ПРП; СС, причем этот код не зависит от жирности буквы и ее наклона.
— Этого достаточно для распознавания текста?
— Одного ПРС-кода, конечно, недостаточно. Например, такой же ПРС-код, как А, имеют буквы Я и Д. Поэтому к нему добавляют другие, метрические признаки, например учет расстояний между различными строками, что позволяет надежно отличить А от Д.
— Как вы — чистый математик — пришли к распознаванию текстов?
— Появление персональных компьютеров в конце 1980-х гг. стимулировало исследования по распознаванию образов. Так, в институте Стеклова при отделе топологии организовался небольшой семинар по этой теме. Начали мы с распознавания рукописных символов. Среди участников-топологов был хороший программист Григорий Непомнящий, который реализовывал возникавшие интересные топологические идеи на привезенном мною из-за границы ПК. Потом появился Виталий Кляцкин из Тулы, который привлек участников семинара к выполнению связанного с распознаванием военного заказа.
Годичная работа над этим заказом привела к появлению уверенного в своих силах сплоченного коллектива программистов-математиков. И в начале 1990-х гг. этот коллектив под моим руководством составил костяк фирмы, взявшейся создать программу оптического распознавания текстов, основанную на открытом мной ПРС-коде, который был нашей коммерческой тайной. Получившаяся у нас тогда программа «Крипт» была одной из лучших на рынке. Например, первая версия FineReader ей заметно уступала. Программу можно было быстро обучить распознавать любой текст. Например, текст на армянском языке.
— Никогда не слышала о такой программе…
— Коммерческое распространение программы потребовало роста фирмы: нужно было готовить подробную документацию, защиту от копирования, драйверы для разных сканеров, подключать словари и многое другое. А в 1995 г. наш главный программист Григорий Непомнящий эмигрировал в США. И наша маленькая фирма не выдержала конкуренции с большими фирмами. После ее «кончины» в 1995 г. я и некоторые мои товарищи поработали еще в оптическом распознавании на конкурентов из Cognitive Technologies, но с 1998 г. я не занимался оптическим распознаванием.
— Вы немало времени и сил посвятили еще одной научной задаче, связанной с суперкомпьютерами. Расскажите, пожалуйста, что такое кривые Пеано и как они связаны с суперкомпьютерами?
— В данный момент у суперкомпьютеров есть такая проблема: задач для них мало. Суперкомпьютеров наделали много, а чем их загрузить? Задача с кривыми Пеано позволяет загрузить суперкомпьютер основательно. Приблизительно эту задачу можно сформулировать так: представьте, что у нас есть n-мерная решетка. Нам нужно ее как-то упорядочить — всем элементам решетки дать номера так, чтобы узлы решетки с близкими номерами находились по возможности недалеко друг от друга.
Эту задачу и решают многомерные кривые Пеано. Например, еще в самом начале компьютерного времени у меня была идея сделать развертку телевизора по кривой Пеано.
Развертка — это строчки на экране. А теперь представьте — пошла помеха. Тогда она выбивает несколько строчек. А кривая Пеано устроена так: если у вас пошла помеха, то она не растянется на весь экран, а свернется. Поэтому телевизор с пеановской разверткой был бы лучше обычного. Помехи меньше бы мешали на экране.

— У вас это получилось?
— Нет. Теоретически все это ясно, есть обоснования, есть кривые, есть формулы. Сделать все это вполне возможно. Но, к сожалению, электронно-лучевые трубки ушли в прошлое, сейчас все телевидение устроено по-другому.
Зато по поводу телевидения у меня есть другая замечательная идея, которую хорошо бы внедрить. Это цифровой двумерный аналог пеановской кривой. Представьте себе, что у нас есть шахматная доска на 64 клетки. Есть палитра цветов — red, green, blue. Для каждого цвета — четыре градации. И тогда у нас получится всего градаций цвета тоже 64, 43, так же как шахматная доска. И теперь каждую клетку шахматной доски нужно раскрасить в один из цветов. Все будут разного цвета. Но нужно раскрасить так, чтобы соседние клетки были окрашены в соседние цвета. Такая непрерывная гамма, где цвет все время меняется.
— Это будет красиво.
— Красиво. Вот это было замечательно сделано обычным компьютером. Обошлись без суперкомпьютера. У нас с сыном (он программист) опубликована статья на эту тему. Я был уверен, что такую раскладку невозможно сделать. Придумал алгоритм, который хорошо сокращал счет. Компьютер считал ночь.
— Вы пытались сделать то, во что не верили?
— Думал, что нельзя. И вдруг компьютер выдал — оказалось, что такая раскладка уникальна. Их существует ровно четыре. Они друг от друга отличаются поворотом. И действительно картинка очень красивая.
— И каким образом вы хотите это внедрить на телевидении?
— Оказывается, в системе PAL/SECAM используют в кодировании цветов так называемый двумерный код Грея. Насколько я помню, там 4 х 4, 16 цветов. Они разложены именно так, чтобы цвета соседних клеточек были соседними. Это прекрасная защита от помех. У них на 16 цветов, а у меня на 64, что намного лучше. Учитывая разрядность процессоров, это может хорошо ложиться на операционную систему. Так что это вещь, которая просто просит внедрения.
— Помимо улучшения качества картинки, осталось еще повысить качество самих передач на ТВ. Знаю, что вы занимались не только распознаванием текстов, но и распознаванием пола, возраста человека. Что это за работа?
— Речь идет о работе в «Яндексе», где я был научным консультантом. Мы решали интересную задачу: когда человек ходит по интернету, его маршрут известен, и нужно было распознать, мужчина это или женщина, с целью таргетированной рекламы. Эта задача была решена.
— Каким образом можно понять, мужчина это или женщина?
— У нас есть достаточно большая база данных людей, про которых известно, мужчины это или женщины. Дальше: мы начинаем смотреть, сайт мужской или женский, уже зная, мужчина или женщина его смотрят, сколько женщин и сколько мужчин туда ходят. Ведь для каждого сайта есть статистика — сколько там было женщин и сколько мужчин. И после этого мы начинаем определять. На основании этих данных мы выдаем формулу, определяющую вероятность того, кто это, мужчина или женщина. Чаще всего мы оказывались правы.
— А почему оказалось невозможным определить возраст человека?
— Потому что возрастов не два, а больше. Вся методика, с которой мы работали, опиралась на эти статистики. И оказалось, что можно получить, вычислить, точно определить количество информации о поле или о возрасте, которая содержится в базе данных. Сколько она содержит информации — вычисляется строго математическое понятие. Было известно, сколько нужно, чтобы обеспечить такую точность, потому что задача определения пола была решена так: распознаватель в половине случаев вообще отказывался распознавать, кто это. А в половине, когда соглашался, угадывал правильно с вероятностью 80%. Требовалось что-то в таком роде.
Тут можно посчитать, сколько информации необходимо для данного задания, чтобы обеспечить заданные параметры распознавания, и сколько есть информации в базе данных.
Я сумел это посчитать и показать, что ее не хватает. А чтобы посчитать, нужно было придумать нечто хитрое. Проблема тут заключается в большом количестве сайтов с малой статистикой. Например, сайт посетил один человек, и все. Какая вероятность того, что следующий посетитель того же пола? И я придумал такой трюк — вторичную статистику. Мы берем эту базу данных и делим ее пополам. Используя только первую половину базы, определяем все сайты с единственным посещением, объединяем и говорим, что это «сайт первого типа». А для объединенного сайта первого типа анализируем уже немалую статистику его посещений из второй половины базы. Эта вторичная статистика и позволяет надежно найти искомые вероятности и аккуратно определить количество информации в базе.
— Как думаете, такие вещи, которые вы придумали, можно использовать для чего-то еще, кроме рекламы, которая уже порядком надоела?
— Да для чего угодно! То, чем мы занимались, это, что называется, Big data. Эти трюки с подсчетом информации, конечно, вещь универсальная. Там еще возможен анализ общего типа, когда мы пытаемся что-то предсказывать. Скажем, поведение. Когда технологии предсказаний развиваются, то мы можем предсказать все что угодно, если, конечно, данные содержат достаточно информации.
— Это хорошо или плохо, когда можно предсказать все что угодно?
— Это не хорошо и не плохо. Это данность. Эта методика работает с большими данными. Данные, с которыми работают в медицине или на бирже, по существу однотипны — это кривые. Кардиограммы и энцефалограммы в медицине или графики изменения биржевых цен, объемов продаж акций. Задача диагностики предынфарктного состояния человека или состояния биржи (канун краха) по существу одинакова. Для всех этих задач используются фрактальные размерности, алгоритмы определения разладки и многое другое. То есть это универсальные методики, которые могут многим спасти жизнь. Так что математика наша вполне прикладная.
Интервью проведено при поддержке Министерства науки и высшего образования РФ и Российской академии наук
Иллюстрации предоставлены Е.В. Щепиным














































{kind=link}