

Янив Эрлих (Yaniv Erlich) из Колумбийского университета и Дина Зелински (Dina Zielinski) из Нью-Йоркского геномного центра разработали метод записи информации на ДНК, позволяющий обойти трудности, связанные с использованием ранее испытанных способов, а также значительно увеличить объем информации на единицу площади. О своих результатах ученые сообщили в публикации в журнале Science.
Человечество производит все больше информации, и объем ее на единицу времени растет экспоненциально. Соответственно, становится все более острой и проблема ее хранения. Развитие науки дало возможность обратиться к самому важному для человека как вида носителю — дезоксирибонуклеиновой кислоте, потому что это носитель выносливый, емкий и заранее снабженный механизмом копирования. Однако предыдущие попытки сталкивались в трудностями в области извлечения информации, например потому, что синтез ДНК, а также некоторые приемы, применяемые в ходе записи, могут привести к неравномерному представлению олигонуклеотидов.
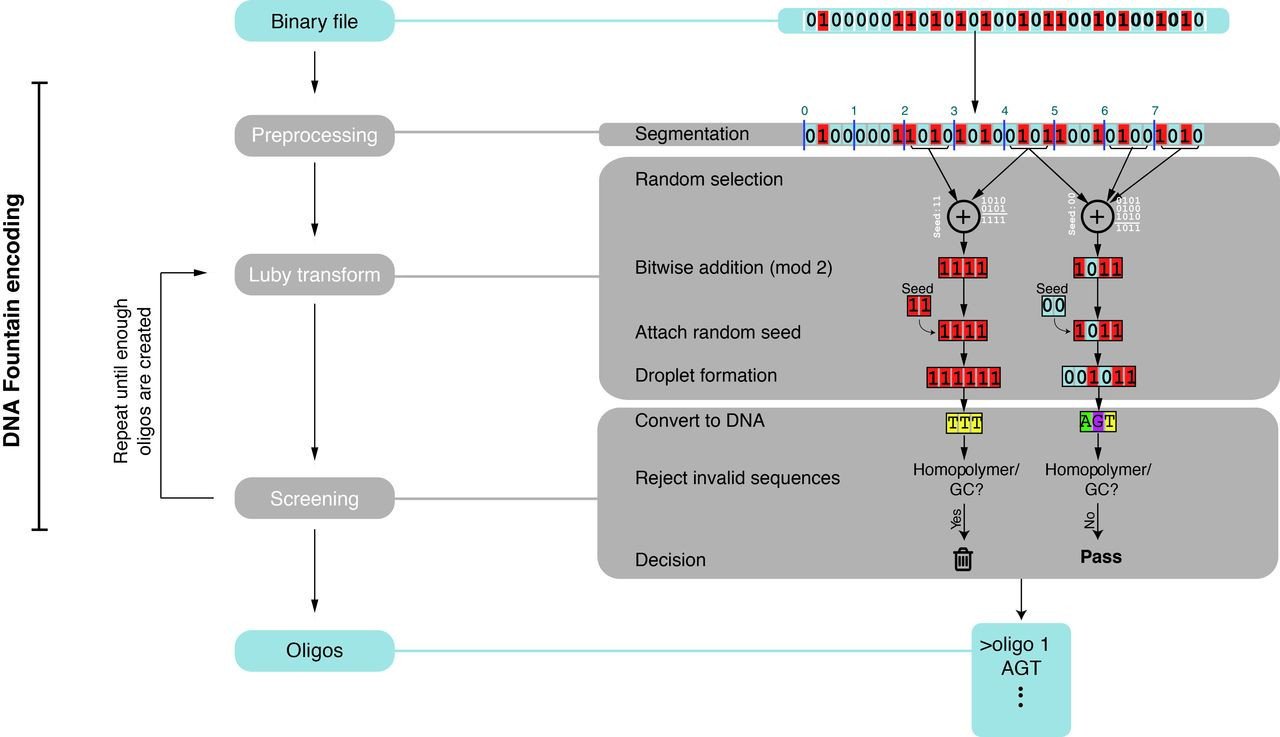
Новый метод, названный «ДНК-фонтан», позволяет не только обойти эти проблемы с олигонуклеотидами, но и хранить на 60% больше информации, чем все ранее предложенные. Он основан на методе кодирования, который предполагает случайную упаковку единиц информации и последующую сборку в заданном порядке — сходным образом работает пересылка информации в интернете, где пакеты данных приходят к адресату в случайном порядке, а потом собираются в порядке нужном.
Чтобы обеспечить нужный режим функционирования носителя информации, чтобы передать «сообщение», кодируется больше олигонуклеотидов, чем нужно, а затем система отдает приоритет сохранным олигонуклеотидам перед поврежденными, чтобы минимизировать количество ошибок. В результате вся сохраненная информация остается доступной, даже если часть «пакетов» потеряна или повреждена.
На практике ученые смогли закодировать файл размером 2146816 байтов, который включал видеоролик, операционную систему с графическим интерфейсом и другие файлы, причем плотность записи составляла 86% от теоретического максимума. Затем они несколько раз скопировали файл и сумели успешно считать копию, несмотря на то, что с каждым копированием ошибки должны накапливаться.























{kind=link}